Tout d'abord, il faut comprendre un principe : Quand on dit qu'un MXF est chiffré, c'est un mensonge. Un MXF n'est pas entièrement chiffré.
Seuls certains KLV auront du chiffrement. Et dans ces derniers, seul un segment de la partie Value sera effectivement chiffré. Tout le reste sera en clair, parfaitement lisible et sans aucun chiffrement.
Par exemple, les KLV dans Header et Footer sont non-chiffrés, et dans les KLV du Body, seules les KLV Essences auront un segment chiffré dans leur partie Value :
Seul les segments en rouge seront chiffrés.
Tout le reste de notre MXF reste en clair, donc non-chiffré.
Ainsi, on peut lire des métadonnées nécessaires pour le déchiffrement des segments chiffrés.
Les éléments nécessaires
Entre un MXF normal et un MXF dit-chiffré, il n'existe que 2 KLV supplémentaires et un nouveau type de KLV :
2 KLV en suppléments dans la partition Header
Des KLV Encrypted Essence Container dans la partition Body
Voici la liste des KLV supplémentaires obligatoires :
Les KLV Header : Cryptographic Framework & Cryptographic Context
Présents dans Header, les deux KLV Cryptographic Framework et Cryptographic Context définissent tout un contexte cryptographique et notamment le type de cryptographie utilisée dans les KLV chiffrés Encrypted Essence Container.
Cryptographic Framework et Cryptographic Context sont simplement des containeurs d'informations qu'on peut ignorer sans problème pour l'instant car sans impact direct avec le processus de déchiffrement de nos données stockées dans Encrypted Essence Container.
En effet, sauf en cas de changement de méthode cryptographique dans les MXF DCP, si vous avez déjà la clef AES, vous pouvez déchiffrer Encrypted Essence directement en appliquant la méthode de déchiffrement que nous verrons ci-dessous.
Nous reviendrons plus en détails sur Cryptographic Framework & Cryptographic Context en peu plus tard.
Les KLV Body : Encrypted Essence Container
Présents obligatoirement dans Body, il faut au moins un Encrypted Essence Container par MXF. Et il n'y a pas de limite théorique aux nombres de containeurs possibles.
Voyons d'abord nos KLV chiffrés, les Encrypted Essence Container.
La cryptographie utilisée
Actuellement, la cryptographie utilisée pour le chiffrement des données est AES-128-CBC :
AES est un algorithme à chiffrement symétrique : une clef unique sert pour le chiffrement et le déchiffrement.
Une clef de chiffrement de 128 bits (16 octets).
Un chiffrement par bloc de bits, chaque bloc sera de 128 bits (16 octets)
Un mode d'opération des blocs Cipher Block Chaining (CBC) : un bloc est chiffré par le résultat du précédent bloc avant d'être chiffré de nouveau avec la clef de chiffrement initiale.
AES est l'algorithme de chiffrement principal, c'est lui qui utilisera la clef de chiffrement initiale pour chiffrer le texte. C'est la partie la plus importante de notre cryptographie. Cipher Block Chaining (CBC) est un mécanisme en supplément qui va renforcer ce chiffrement.
Le sujet étant relativement long et (presque) complexe, si vous souhaitez une explication de comment marche cette cryptographie, vous pouvez lire notre paragraphe spécifique à la cryptographie AES-CBC.
Notez que si vous savez déjà comment marche cet algorithme, ce paragraphe est parfaitement dispensable. Tout ce que vous avez à retenir pour l'instant est que pour chiffrer et déchiffrer un contenu AES-128-CBC, il vous faudra :
Un contenu en clair (pour le chiffrement) ou chiffré (pour le déchiffrement)
Une clef de 16 octets (128 bits)
Un Initialization Vector (IV) de 16 octets (128 bits)
A partir de cela, nous pouvons entrer dans le vif du sujet.
A l'intérieur des KLV chiffrés
Pour résumé ce qu'on a vu dans les précédents chapitres :
Les KLV chiffrés sont des Encrypted Essence Container.
Leurs types sont Variable-Length Pack : Suite d'items avec un Length et une Value, l'un à la suite de l'autre.
L'Universal Label pour Encrypted Essence Container est 060e2b34.02040101.0d010301.027e01001
Comme nous l'avons vu dans notre chapitre sur les types de KLV, chaque item sera une métadonnée spécifique qui nous servira dans le traitement de nos données, par exemple, trouver l'emplacement du segment chiffré, initialiser le contexte cryptographique, etc.
La cryptographie des KLV est relativement simple car elle utilise de la cryptographie ouverte et reconnue (AES-CBC) mais possèdent certaines subtilités (deux pour être précis) à prendre en compte pour pouvoir déchiffrer un MXF correctement.
Pour comprendre ces subtilités, nous allons faire un focus sur la partie Value d'un KLV chiffré :
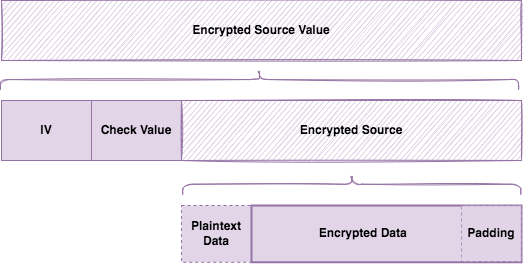
Les éléments en pointillés sont optionnels et peuvent ne pas exister (comme Plaintext Data ou Padding)
Pour rappel, un item possède son propre Length (en vert) et sa propre Value (en violet).
La taille de ces Length est variable car soumis à notre fameux format BER - que nous avons déjà vu dans la section Length du KLV. Actuellement, et malgré son format, elles sont toujours de 4 octets et débutent par 0x83 indiquant un BER variable avec 3 octets pour encoder la taille (ex. 0x83000000)
Voici un descriptif rapide de chaque item : (n'oubliez pas que chaque item démarre par son propre Length)
Cryptographic Context Link (UUID, 16 octets) : est l'identifiant faisant le lien entre notre KLV Essence et le KLV Cryptographic Context dans la section Context ID. Cet identifiant sera commun à chaque KLV Encrypted Essence, voyez cela comme un identifiant de groupe (GID).
Plaintext Offset (Uint64, 8 octets) : est le nombre d'octets où le chiffrement va commencer dans notre partie "Encrypted Source". C'est notre première subtilité : Il peut arriver qu'une partie de notre partie "Encrypted Source" ne soit pas chiffrée. Si c'est le cas, alors sa valeur sera supérieure à 0.
Pour donner un rapide exemple, si Plaintext Offset est à 128, cela indiquera que les 128 premiers octets de Encrypted Source ne seront pas chiffrés.
Pour l'instant, la plupart des MXF sortant des laboratoires cinématographiques n'utilisent pas ce principe et chiffrent entièrement le contenu.
Nous reviendrons sur cette partie plus en détail un peu plus tard.
Source Key (8 octets) : est un simple identifiant de type "Universal Label" qui détermine le type de contenu. Les valeurs possibles sont (liste non-exhaustive) :
Type
Universal Label
Picture Essence
060e2b34.01020101.0d010301.15010801
Sound Essence
060e2b34.01020101.0d010301.16010101
Timed Text Essence
060e2b34.0101010c.0d010509.01000000
Timed Text Essence
060e2b34.01020101.0d010301.17010b01
Immersive Audio (Dolby Atmos)
060e2b34.01020105.0e090601.00000001
Source Length (Uint64, 8 octets) : est la taille d'origine de notre contenu (avant chiffrage). Ce chiffre sera toujours égal ou inférieur à la taille des données chiffrées. Cela est dû au fait que le chiffrement s'effectue que sur des blocs de 16 bits, donc la taille de la partie chiffrée sera toujours un multiple de 16. Si la source n'est pas un multiple de 16, il sera complété par des données dit de rembourrage (padding)
Encrypted Source Value (taille variable et définie dans son Length) :
C'est notre partie où se trouve notre chiffrement.
Le nom Encrypted Source Value peut induire en erreur car il semble indiquer que Encrypted Source Value est notre contenu chiffré. Or, cette partie est un containeur incluant des éléments nécessaires au déchiffrement de notre contenu chiffré et stocké dans Encrypted Data.
Notez - et c'est important - que ces éléments sont l'un à la suite de l'autre sans aucun Length entre eux. Vous ne pouvez déterminer la taille de chaque que parce que certains sont fixes (IV et Check Value font 16 octets chacun) et que d'autres ont leurs tailles définies autre part dans Value :
La taille de Plaintext Data est déterminée par l'item Plaintext Offset
La taille d'Encrypted Data ne s'évalue qu'en récupérant le Length de Encrypted Source Value et en retranchant la taille de IV, Check Value et Plaintext Data)
Voici un descriptif des différents éléments dans Encrypted Source Value :
Initialization Vector (IV) (16 octets) : est notre initialisateur du moteur cryptographique.
Check Value (16 octets) : est une valeur fixe définie par la norme qui permet de savoir si le déchiffrement se passe bien, indépendamment du type de contenu. C'est notre seconde subtilité. Nous reviendrons également sur cette partie plus en détail un peu plus tard.
Plaintext Data (taille variable définie dans Plaintext Offset) : est une portion - qui peut ne pas être présent - non-chiffrée provenant de notre source. Ainsi, on peut avoir tout ou partie de notre source en clair. Nous verrons ceci plus en détail dans la partie Etude de la value d'un KLV chiffré avec Plaintext Offset
Encrypted Data (taille variable) : est -enfin- notre partie chiffrée ! (le padding en fait partie)
Comme vous le voyez, le nom n'indique pas forcément tout ce qui se cache à l'intérieur de cette partie.
Les éléments suivants sont optionnels, ils seront présents seulement si Message Integrity Code (MIC) est défini :
TrackFile ID (UUID, 16 octets) : est un identifiant unique qui identifie le TrackFile. Chaque frame dans ce MXF aura le même identifiant. Cet identifiant est aussi l'identifiant AssetUUID du MXF qu'on retrouvera dans :
Source Clip ➝ Package UID,
Source Package ➝ Package UID
Essence Container Data ➝ Linked Package UID
Sequence Number (Uint64, 8 octets) : est un numéro qui s'incrémente à chaque nouvelle frame stockée dans ce MXF.
Message Integrity Code (MIC) (20 octets) : est la somme de contrôle (checksum). L'algorithme utilisé est défini dans le KLV Cryptographic Context, section MIC Algorithm. Actuellement, l'algorithme utilisé est HMAC-SHA1-128.
Pour des raisons de simplification, ces derniers éléments optionnels seront écartés dans les paragraphes "Etude de la Value d'un KLV chiffré". Ils seront expliqués en détail dans le paragraphe "Message Integrity Code".
Etude de la Value d'un KLV chiffré
Pour notre étude, nous ne travaillerons que sur la partie Value d'un KLV Encrypted Essence :
Et notamment sur cette partie :
Qui - résumé et dans sa plus simple apparence - nous donne ceci :
Cependant, vous remarquez qu'il existe un élément en plus par rapport à un chiffrement AES-CBC classique : nous avons un Check Value entre notre Initialization Vector (IV) et notre Encrypted Data, et nous allons voir ce que c'est.
Le bloc intermédiaire de vérification "Check Value"
C'est notre première subtilité !
Check Value est un bloc de 16 octets (128 bits) inséré entre l'Initialization Vector (IV) et notre Encrypted Source (qui intègre Plaintext Data et Encrypted Data)
Check Value est une valeur fixée par avance et placée comme "en-tête" des données chiffrées.
La valeur en clair est (en hexadécimal) :
43 48 55 4B43 48 55 4B43 48 55 4B43 48 55 4B
En version lisible :
CHUKCHUKCHUKCHUK
Elle sert principalement à vérifier rapidement si le déchiffrement s'applique bien, même si nous ne connaissons pas la nature ni le type des données chiffrées.
Par exemple, si nous avions un KLV d'une image d'un format propriétaire dont nous ne connaissons rien, nous saurions que nous avons pu déchiffrer la partie chiffrée sans avoir besoin de manipuler l'image en question.
Cela à plusieurs avantages :
Pouvoir vérifier que les 16 premiers octets du segment chiffré et déterminer si le chiffrement est correctement appliqué (pas besoin de lire les autres octets ni même de manipuler l'essence)
Pouvoir vérifier rapidement chaque KLV chiffré et déterminer si le chiffrement est correctement appliqué sur l'ensemble du MXF : Si vous avez 10.000 frames, vous avez donc un IV et un CheckValue dans le calcul : 32 octets * 10.000 = 32 Ko au lieu de Mo (ou même de Go) de données à vérifier.
Quand nous crééons un KLV Encrypted Essence, le Check Value fait partie intégrante du contenu chiffré, il suivra aussi le canal cryptographique avec la partie Encrypted Data.
Pis, sans Check Value dans le canal cryptographique, Encrypted Data ne pourra jamais être déchiffré. Si vous vous souvenez, chaque bloc (de 16 octets) est dépendant de son prédécesseur. Ainsi Check Value se comporte comme s'il était le tout premier bloc.
Et cela fait toute la différence dans notre processus de déchiffrement que nous allons voir maintenant.
Etude d'un KLV chiffré normal
Lecture de la structure de Value
Nous allons d'abord étudier la Value d'un KLV chiffré normal :
La source a été totalement chiffrée
Il n'existe pas de partie Plaintext Data.
Voici un exemple de Value d'un KLV Encrypted Essence avec de véritables données :
Avec un éditeur hexadécimal, voici les premiers d'octets de la Value d'un KLV Encrypted Essence :
Chaque item est positionné l'un après l'autre avec sa taille (en vert) et sa valeur.
Voici un code Python très simpliste pour parser la Value d'un KLV Encrypted Data :
import sys
with open(sys.argv[1], "rb") as file:
print("CryptographicContextLink Length : %s" % file.read(4).hex())
print("CryptographicContextLink Value : %s" % file.read(16).hex())
print("PlaintextOffset Length : %s" % file.read(4).hex())
print("PlaintextOffset Value : %s" % file.read(8).hex())
print("SourceKey Length : %s" % file.read(4).hex())
print("SourceKey Value : %s" % file.read(16).hex())
print("SourceLength Length : %s" % file.read(4).hex())
print("SourceLength Value : %s" % file.read(8).hex())
print("Encrypted Source Length : %s" % file.read(4).hex())
print("Encrypted Source Value - IV : %s" % file.read(16).hex())
print("Encrypted Source Value - CheckValue : %s" % file.read(16).hex())
print("Encrypted Source Value - Encrypted Data : %s" % file.read(16).hex())
Ce code se veut ultra-simpliste pour la compréhension. Dans le meilleur des mondes, il faudrait lire chaque Length, les convertir puis lire les Values avec leur bonne taille. Mais vu que la norme indique des tailles fixes, autant en profiter pour l'instant :)
Il faudrait également convertir Encrypted Source Length pour l'utiliser dans la lecture complète (ou par segment) de notre Encrypted Source Value. Ici, nous ne lirons que les 16 premiers octets.
Et enfin, on ne gère pas le Plaintext Offset, qu'on verra au paragraphe suivant :)
# mxf-encrypted-parse.py KLVEncryptedEssenceContainer.value.bin
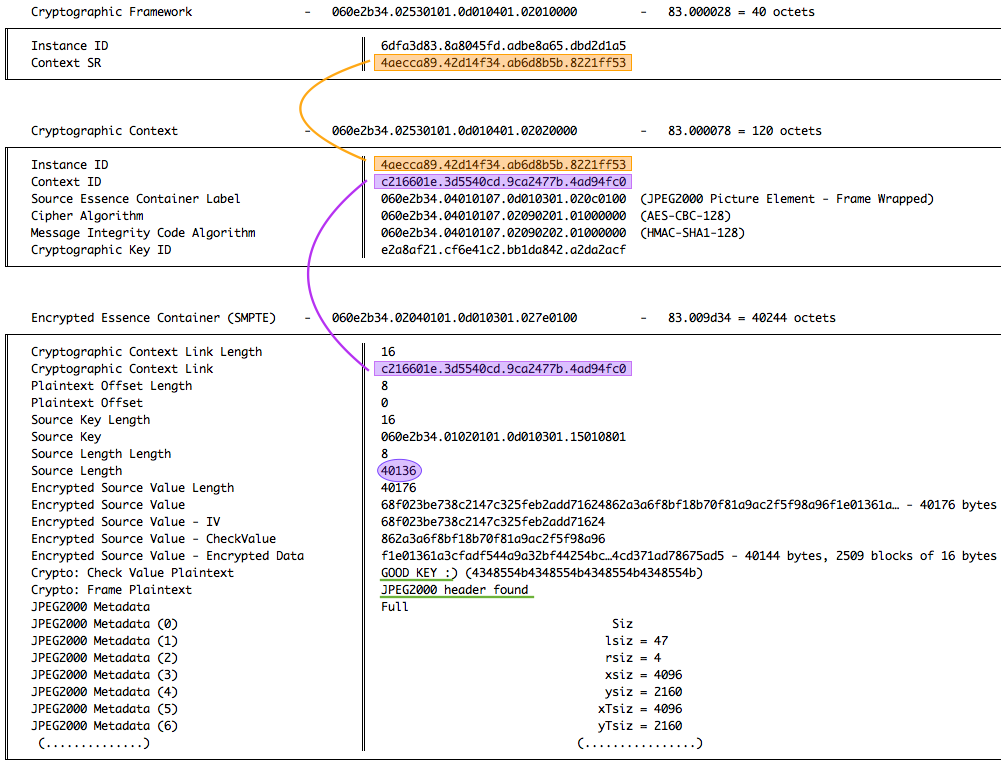
CryptographicContextLink Length : 83000010
CryptographicContextLink Value : 67bec4fc40de4996aac7fa42a6b0ed5e
PlaintextOffset Length : 83000008
PlaintextOffset Value : 0000000000000000
SourceKey Length : 83000010
SourceKey Value : 060e2b34010201010d01030115010801
SourceLength Length : 83000008
SourceLength Value : 0000000000009cc8 <===================== 40136
Encrypted Source Length : 83009cf0 <===================== 40176
Encrypted Source Value - IV : 765a067b36dfd2e89da94a9c6af0902f <===== 16
Encrypted Source Value - CheckValue : 7d95b3c594116732ed0b2d9b13ac5283 <===== 16
Encrypted Source Value - Encrypted Data : 9c52432ad90a1bba64fd0ac5c604a1c9 <===== 40144
Comme vous constatez, chaque Length est au format BER - facilement identifiable grâce à leur 0x83. On voit que les Values intégrant des UUID (donc de 16 octets) auront 0x10 (16 en décimal) et que les tailles ne nécessitent que des Values de 8 octets, donc 0x08 (8 en décimal).
Une exception avec Encrypted Source Length - facilement compréhensible - qui possède une grande valeur 0x009cf0 (40176 en décimal). Notre Encrypted Source Value (IV, CheckValue et Encrypted Data) sera donc de 40.176 octets. Étant donné que IV et CheckValue sont de 16 octets chacun, nous savons donc que Encrypted Data sera de 40.144 octets (40176 - 32)
Si on décode SourceLength Value, nous constatons que la taille de la source était de 40.136 octets. Notre Encrypted Data est de 40.144 octets (40144 - 40136), nous savons donc que son padding est de 8 octets. C'est parfaitement normal, la taille d'origine - 40.136 octets - n'est pas un multipe de 16, et notre chiffrement AES-128-CBC nécessite que des blocs de 16 octets. Il faut donc bourrer le dernier bloc avec des données inutiles qu'on écartera après déchiffrement.
À partir de là, nous avons tous les éléments nécessaires pour un déchiffrement :
Notre Check Value : 7d95b3c594116732ed0b2d9b13ac5283
Notre Encrypted Data : 9c52432ad90a1bba64fd0ac5c604a1c9 (16 octets seulement)
Avec une clef AES, nous pouvons lancer un processus de déchiffrement.
Déchiffrement de nos données stockées dans Encrypted Data
En se focalisant sur la partie Encrypted Source Value, voici le processus de déchiffrement :
Le processus de déchiffrement est relativement simple : nous utilisons l'IV pour initialiser le déchiffrement et on utilisera comme premier bloc, la CheckValue. Puis, nous passons directement à notre contenu chiffré Encrypted Data.
Pendant (ou après) le processus de déchiffrement, nous aurons écarté le résultat du déchiffrement de Check Value et le padding inutile de notre Encrypted Data. La taille de notre source déchiffrée sera la même que celle d'origine conservée dans l'item Source Length (si ce n'est pas le cas, c'est qu'il y a eu un problème :)
En pseudo-code, voici le processus de déchiffrement de notre Encrypted Source Value :
# On initialise le moteur cryptographique AES-CBC
init_aes_cbc_engine( aeskey, iv )
# On déchiffre le premier bloc "CheckValue"
decrypt_block( checkvalue )
# On déchiffre chaque bloc venant de Decrypted Data
foreach block from decrypted_data :
plaintext += decrypt_block( block )
Vous remarquerez que le résultat du premier appel à decrypt_block n'est pas ajouté à notre résultat final (appelé plaintext). C'est normal, le déchiffrement de checkvalue n'est pas le contenu de notre source. Si nous récupérons le résultat, nous aurions tout simplement la valeur CHUKCHUKCHUKCHUK qui n'appartient bien évidemment pas à notre contenu initial :)
Ce premier appel de decrypt_block avec checkvalue permet de lancer le processus de déchiffrement juste avant celui de Decrypted Data.
Chaque appel de decrypt_block sur un bloc de Decrypted Data permet d'obtenir une partie de la source déchiffrée. Nous ajoutons donc chaque bloc déchiffré à notre plaintext.
Voici un exemple concret de code Python avec les différents éléments nécessaires d'une Value d'un KLV chiffré (IV, CheckValue et les 16 premiers octets de l'Encrypted Data) :
from cryptography.hazmat.primitives.ciphers import ( Cipher, algorithms, modes )
from cryptography.hazmat.backends import default_backend
aes_key = b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
iv = b'\x76\x5a\x06\x7b\x36\xdf\xd2\xe8\x9d\xa9\x4a\x9c\x6a\xf0\x90\x2f'
checkvalue = b'\x7d\x95\xb3\xc5\x94\x11\x67\x32\xed\x0b\x2d\x9b\x13\xac\x52\x83'
encrypted_data = b'\x9c\x52\x43\x2a\xd9\x0a\x1b\xba\x64\xfd\x0a\xc5\xc6\x04\xa1\xc9'
# On définit le moteur cryptographique
cipher = Cipher(
algorithms.AES(key=aes_key),
modes.CBC(initialization_vector=iv),
backend=default_backend()
)
decryptor = cipher.decryptor()
# On rajoute CheckValue dans le processus de déchiffrement
decryptor.update(data=checkvalue)
# On déchiffre notre message chiffré
plaintext = decryptor.update(data=encrypted_data)
# Notre entête JPEG2000 (16 octets)
print(plaintext.hex())
# Résultat: ff4fff51002f00040000100000000870
Notre variable plaintext a la valeur ff4fff51002f00040000100000000870.
Les valeurs 0xFF 0x4F 0xFF 0x51 représentent un entête JPEG2000.
Déchiffrement accompli !
Notez que le retour de decryptor.update(data=checkvalue) serait CHUKCHUKCHUKCHUK.
Bien entendu, notre exemple ne déchiffre que les 16 premiers octets. Pour déchiffrer l'ensemble de Decrypted Data, il suffit d'appliquer la fonction .update() sur les blocs suivants.
Notez également qu'on ne parle pas du padding actuellement : il faudra "couper" le padding avant la sortie finale - notamment grâce à Source Length qui nous indique la taille d'origine du fichier.
Comme vous le voyez, la différence entre un déchiffrement AES-CBC classique et un déchiffrement AES-CBC KLV est la présence de notre Check Value. Sans la ligne de déchiffrement Check Value, notre source déchiffrée serait totalement différente et donc totalement inexploitable.
Etude de la Value d'un KLV chiffré avec Plaintext Offset
Voici notre seconde subtilité après la Check Value : celui du Plaintext.
Par convention dans ce paragraphe, l'item indiquant la taille du segment non-chiffré sera nommé Plaintext Offset et le segment non-chiffrée dans la partie chiffrée sera nommée Plaintext Data (nom non-officiel) :
Alors qu'est-ce que c'est cette histoire de Plaintext Offset et Plaintext Data ?
Selon la norme SMPTE 429-6, il est possible d'avoir une partie du segment Encrypted Data qui ne soit pas du tout chiffrée, appelé Plaintext Data. Cette fonctionnalité permet d'avoir accès aux entêtes des essences directement depuis Encrypted Data sans avoir à déchiffrer l'ensemble d'Encrypted Data.
Voici les quelques règles majeures concernant Plaintext Offset / Plaintext Data :
Si la valeur de Plaintext Offset est supérieure à 0, il détermine la taille de Plaintext Data et donc de sa présence dans la partie Encrypted Source Value.
Si Plaintext Data est présent, il sera placé entre Check Value et Encrypted Data.
Les données en clair dans Plaintext Data s'arréteront là où les données chiffrés dans Encrypted Data débuteront.
Par exemple, si notre source était 0123456789 et que Plaintext Data est 01234,
alors Encrypted Data sera le chiffrement de 56789.
Plaintext Data sont les premiers octets de notre source, non-chiffrées.
Et Encrypted Data, la suite de notre source, chiffrée.
Littéralement, les premiers octets de notre source sont copiés directement dans Plaintext Data.
Voici un code Python très simpliste pour parser la Value d'un KLV avec du Plaintext Offset :
import sys
with open(sys.argv[1], "rb") as file:
print("CryptographicContextLink Length : %s" % file.read(4).hex())
print("CryptographicContextLink Value : %s" % file.read(16).hex())
print("PlaintextOffset Length : %s" % file.read(4).hex())
# Convertion valeur hexadécimal en décimal (integer)
plaintextOffset = int.from_bytes(
file.read(8),
byteorder='big'
)
print("PlaintextOffset Value : %s" % plaintextOffset)
print("SourceKey Length : %s" % file.read(4).hex())
print("SourceKey Value : %s" % file.read(16).hex())
print("SourceLength Length : %s" % file.read(4).hex())
print("SourceLength Value : %s" % file.read(8).hex())
print("Encrypted Source Length : %s" % file.read(4).hex())
print("Encrypted Source Value - IV : %s" % file.read(16).hex())
print("Encrypted Source Value - CheckValue : %s" % file.read(16).hex())
print("Encrypted Source Value - Plaintext Data : %s" % file.read(plaintextOffset).hex())
print("Encrypted Source Value - Encrypted Data : %s" % file.read(16).hex())
# mxf-encrypted-parse.py KLVEncryptedEssenceContainerWithPlaintextOffset.value.bin
CryptographicContextLink Length : 83000010
CryptographicContextLink Value : 1f5d16c78fbe4dd990b567533fd9bd34
PlaintextOffset Length : 83000008
PlaintextOffset Value : 16
SourceKey Length : 83000010
SourceKey Value : 060e2b34010201010d01030115010801
SourceLength Length : 83000008
SourceLength Value : 0000000000009cc8 <===================== 40136
Encrypted Source Length : 83009cf0 <===================== 40176
Encrypted Source Value - IV : b4d6394b5d1ad1c7bdfcd6d300cad5de <==== 16
Encrypted Source Value - CheckValue : 3aabe914eaed2d714584cfe5bb8cc762 <==== 16
Encrypted Source Value - Plaintext Data : ff4fff51002f00040000100000000870 <==== 16
Encrypted Source Value - Encrypted Data : 79de6f3aab54fb6b0f8b228371a40cd8 <==== 40144
On constate que dans notre Plaintext Data, nous avons bien notre entête JPEG2000 0xff 0x4f 0xff 0x51 en clair et lisible. La taille du Plaintext Data est de 36 octets.
Notez que ce code marche aussi sa version sans Plaintext Offset : Et oui, vu que le PlaintextOffset Length sera à 0, notre Plaintext Data sera vide et il passera de suite à Encrypted Data :)
Tout comme notre précédent code, nous avons aussi tous les éléments nécessaires pour un déchiffrement dans ce contexte précis :
Avec une clef AES, nous pouvons lancer un processus de déchiffrement.
Déchiffrement de nos données (avec notre Plaintext Data)
En se focalisant sur la partie Encrypted Source Value, voici le processus de déchiffrement avec Plaintext Data :
Voyez la petite subtilité en action : Comme nous l'avons vu précédemment, nous allons appliquer un déchiffrement en utilisant IV, CheckValue et bien entendu Encrypted Data. Plaintext Data sera simplement copié en début de notre source déchiffrée.
D'un point de vue programmatique, nous avons plusieurs choix :
Soit vous lancez votre chiffrement en lisant l'IV, puis Check Value et vous vous déplacez directement vers Encrypted Data en enjambant Plaintext Data, pour revenir le chercher après afin de l'insérer en début de votre source déchiffrée : un peu laborieux mais pourquoi pas.
Soit vous lancez le déchiffrement dès le début, et quand vous passez sur Plaintext Data, il suffit de bypasser le chiffrement : moins laborieux et ne demande pas de courir de droite à gauche dans le fichier.
Soit vous utilisez votre propre idée :)
En pseudo-code, voici le processus de déchiffrement de notre Encrypted Source Value avec notre Plaintext Data :
# On initialise le moteur cryptographique AES-CBC
init_aes_cbc_engine( aeskey, iv )
# On applique le premier bloc "CheckValue"
decrypt_block( checkvalue )
# On copie directement "Plaintext Data" sans traitement
plaintext = plaintext_data
# On déchiffre chaque bloc venant de Decrypted Data
foreach block from decrypted_data :
plaintext += decrypt_block( block )
Vous constatez qu'entre notre précédente version et celle-ci, il n'existe qu'une ligne de différence, celle de copier directement Plaintext Data dans notre source déchiffrée, juste avant de reprendre le déchiffrement des différents blocs.
Voici donc notre précédent exemple de code Python agrémenté de la gestion du Plaintext Offset :
from cryptography.hazmat.primitives.ciphers import ( Cipher, algorithms, modes )
from cryptography.hazmat.backends import default_backend
aes_key = b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
iv = b'\xb4\xd6\x39\x4b\x5d\x1a\xd1\xc7\xbd\xfc\xd6\xd3\x00\xca\xd5\xde'
checkvalue = b'\x3a\xab\xe9\x14\xea\xed\x2d\x71\x45\x84\xcf\xe5\xbb\x8c\xc7\x62'
plaintext_data = b'\xff\x4f\xff\x51\x00\x2f\x00\x04\x00\x00\x10\x00\x00\x00\x08\x70'
encrypted_data = b'\x79\xde\x6f\x3a\xab\x54\xfb\x6b\x0f\x8b\x22\x83\x71\xa4\x0c\xd8'
# On définit le moteur cryptographique
cipher = Cipher(
algorithms.AES(key=aes_key),
modes.CBC(initialization_vector=iv),
backend=default_backend()
)
decryptor = cipher.decryptor()
# On rajoute CheckValue dans le processus de déchiffrement
decryptor.update(data=checkvalue)
# On copie simplement notre Plaintext Data
plaintext = plaintext_data
# On déchiffre notre message chiffré
plaintext += decryptor.update(data=encrypted_data)
# Notre entête JPEG2000 (16 octets)
print(plaintext.hex())
# Résultat :
# ff4fff51002f0004000010000000087000000000000000000000100000000870
# ff4fff51002f00040000100000000870 <== partie plaintext_data
# 00000000000000000000100000000870 <== partie encrypted_data déchiffrée
Le résultat est -bien entendu- un entête JPEG2000 de part la valeur initiale de Plaintext Data, mais le reste est bien sa suite déchiffrée qu'on peut voir dans l'output de notre JPEG2000 disponible ici :
Maintenant que nous avons fait un tour de ce qu'est KLV Encrypted Essence, nous allons aller une étape supplémentaire : un parseur MXF qui ne va lire que les KLV Encrypted Essence et en extraire les données déchiffrés.
Toujours pour des raisons de simplicité, on fera l'impasse sur pas mal d'éléments comme des vérifications d'usage, un (bon) calcul BER et autres joyeusetés.
Première étape, on va lire un MXF et détecter chaque KLV sans distinction :
# Conversion en int
def to_int(length : bytes = b'') -> int:
return int.from_bytes(length, byteorder='big')
with open("encrypted-key-00000000000000000000000000000000-plaintextoffset.mxf", "rb") as file:
while True:
# Key : Universal Label
key = file.read(16)
# End of file
if not key:
break
# Length (BER format)
length = to_int(file.read(4)[1:]) # BER format - read last 3 bytes
# Value
value = file.read(length)
# Show each KLV
print("{key} - {length:>6d} - {data}...".format(
key = key.hex(),
length = length,
data = value[0:16].hex()
))
On remarque que nos données sont correctement structurées : nous avons nos Universal Label, puis la taille de chaque Value et les débuts de chaque Value.
Rapidement, on distingue un KLV avec une taille plus imposante que les autres : c'est notre KLV contenant notre essence. Pour être plus précis, l'Universal Label correspond à celui d'un KLV Encrypted Essence Container : 060e2b34020401010d010301027e0100.
Nous allons maintenant filtrer nos KLV pour ne conserver que nos Encrypted Essence Container :
# Value
value = file.read(length)
+---------------------------------------------------------------------+
| # KLV SMPTE & Interop
| if key.hex() != "060e2b34020401010d010301027e0100" and \ |
| key.hex() != "060e2b34020401070d010301027e0100": |
| continue |
+---------------------------------------------------------------------+
# Show each KLV
print("{key} - {length:>6d} - {data}...".format(
Il existe d'autres méthodes pour filtrer, comme comparaison bytes à bytes, ou bien trouver la bonne catégorie, la bonne version, etc. Mais utilisons plutôt une méthode rapide, simple et lisible pour l'instant avec une simple conversion de bytes en string à l'aide de .hex() et notre Universal Label.
Maintenant, nous allons lire la Value de notre KLV.
Pour rappel, la structure Variable-Length Value est une suite d'items ne contenant que des item.Length et item.Value.
item.Length est de 4 octets
item.Value est officiellement toujours variable, mais dans notre cas, nous aurons principalement des tailles de 8 octets, 16 octets et le reste véritablement variables.
La taille 8 octets est généralement utilisée pour stocker une valeur décimale, comme ... une taille :) par exemple la taille du Plaintext Offset, la taille d'origine de la source. Avec 8 octets, vous pouvez avoir une valeur décimale jusqu'à ( 264 -1 ) soit 18.446.744.073.709.551.615, ce qui est normalement assez large :)
La taille 16 octets est généralement utilisée pour stocker un UUID, comme Cryptographic Context Link ou Source Key.
La taille variable est utilisée pour notre Encrypted Source Value qui va stocker notre essence.
J'utilise io.BytesIO car cela permet d'utiliser des fonctions I/O - comme read(), write(), seek(), tell(), mais on pourrait très bien faire data[0:4] ou même memoryview.
Notre output nous donne maintenant :
060e2b34020401010d010301027e0100 - 40300 - 830000101f5d16c78fbe4dd990b56753...
CryptographicContextLink Length : 83000010
CryptographicContextLink Value : 1f5d16c78fbe4dd990b567533fd9bd34
PlaintextOffset Length : 83000008
PlaintextOffset Value : 16 bytes
SourceKey Length : 83000010
SourceKey Value : 060e2b34010201010d01030115010801
SourceLength Length : 83000008
SourceLength Value : 40136 bytes
Encrypted Source Length : 40176 bytes
Encrypted Source Value - IV : b4d6394b5d1ad1c7bdfcd6d300cad5de
Encrypted Source Value - CheckValue : 3aabe914eaed2d714584cfe5bb8cc762
Encrypted Source Value - Plaintext Data : ff4fff51002f00040000100000000870
Encrypted Source Value - Encrypted Data : 79de6f3aab54fb6b0f8b228371a40cd8...
Nous constatons que, dans Plaintext Data, nous voyons nos fameux 0xff4ffff5 de nos headers JPEG2000, ce qui indique que notre parsing se déroule correctement pour l'instant.
Maintenant que nous avons nos principaux éléments pour un déchiffrement, poursuivons dans le vif du sujet, nous allons rajouter notre coeur cryptographique à l'intérieur de notre parseur.
import io
+------------------------------------------------------------------------+
| from cryptography.hazmat.primitives.ciphers import ( Cipher, algorithms, modes )
| from cryptography.hazmat.backends import default_backend
+------------------------------------------------------------------------+
(...)
print("Encrypted Source Value - Encrypted Data : %s..." % encryptedData[0:16].hex())
+------------------------------------------------------------------------+
| # Set cryptographic engine
| cipher = Cipher(
| algorithms.AES(key=b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'),
| modes.CBC(initialization_vector=IV),
| backend=default_backend()
| )
| decryptor = cipher.decryptor()
|
| # add CheckValue on decryption workflow
| decryptor.update(data=checkValue)
|
| # add PlaintextData directly to Plaintext
| plaintext = plaintextData
|
| # add chunk of encryptedData to Plaintext
| encryptedData = io.BytesIO(encryptedData)
| while True:
| chunk = encryptedData.read(16)
| if not chunk:
| break
| plaintext += decryptor.update(data=chunk)
|
| print("Plaintext Source Value : %s" % len(plaintext))
| print("Padding: %d" % (len(plaintext) - sourceLengthValue))
|
| # write Plaintext to file
| with open("output_%d.j2c" % file.tell(), "wb") as f:
| f.write(plaintext)
+------------------------------------------------------------------------+
Nous initialisons notre moteur cryptographique avec notre IV, et notre clef AES (0x00).
On rajoute notre Plaintext Data directement dans notre sortie (plaintext).
Parce que io.BytesIO apporte son lot de fonctions utiles, nous l'utilisons également ici, mais vous pouvez tout autant lire directement encryptedData par portion avec un offset pour décaler à chaque fois le segment en cours de lecture.
Nous lisons des portions (chunk) de Encrypt Data d'une taille de 16 octets que nous passons à notre fonction .update().
Si nous lançons maintenant notre programme, nous aurons notre frame JPEG2000 :
39K output_56844.j2c
Les numéros n'ont pas d'intérêt, ils sont simplement là pour différencier les différentes sorties et ne représentent que le pointeur de position dans le fichier au moment de l'écriture.
Vous remarquerez que nous n'avons pas traité notre padding : il se trouve encore dans notre output.
Regardons la fin de notre output d'une de nos frames JPEG2000 :
Par ailleurs, nous savons qu'un JPEG2000 se termine par 0xffd9.
Ces 8 octets sont nos octets de padding pour compléter notre dernier bloc de 16 octets.
Le moyen de supprimer ce padding est de prendre sa taille d'origine stockée dans Source Length Value et de l'utiliser pour couper avant la finalisation ou l'écriture dans le fichier :
+------------------------------------------------------------------------+
| # write Plaintext to file
| with open("output_%d.j2c" % file.tell(), "wb") as f:
| f.write(plaintext[0:sourceLengthValue])
+------------------------------------------------------------------------+
Et voila, votre output sera parfaitement déchiffré et sauvegardé, il est comme l'original :
# shasum -a 256 output_56844.j2c frame.j2c
b469a8333a8ad708becdfc7544f180c1198b12722a2051b90c66b5ba58ded825 output_56844.j2c
b469a8333a8ad708becdfc7544f180c1198b12722a2051b90c66b5ba58ded825 frame.j2c
Les checksums sont identiques, preuve que le processus de déchiffrement est complet.
Nous pourrions optimiser ce code, par exemple, placer l'écriture au moment du déchiffrement, cela permet d'éviter de construire un énorme buffer et d'utiliser un petit de 16 octets - au risque d'avoir plus appels systèmes pour les entrées/sorties. Et bien d'autres optimisations encore, amusez-vous en utilisant son code source :)
Les KLV Headers en détail
Comme nous avons vu précédemment, nous avons deux KLV spécifiques dans les Headers : Cryptographic Framework & Cryptographic Context
Avant de partir en détail sur nos deux KLV supplémentaires, voici un schéma expliquant les liaisons entre eux :
Lien vers Encrypted Essence -> Cryptographic Context Link
Source Essence Container Label
UUID
16 octets
FFFDdynamique
060e2b34.01010109.06010102.02000000
Identifiant du type de source
Cipher Algorithm
UUID
16 octets
FFFCdynamique
060e2b34.01010109.02090301.01000000
Identifiant du type de cryptographie
MIC Algorithm
UUID
16 octets
FFFBdynamique
060e2b34.01010109.02090302.01000000
Identifiant du type de cryptographie
Cryptographic Key ID
UUID
16 octets
FFFAdynamique
060e2b34.01010109.02090301.02000000
Identifiant pour la clef
( GenerationUID )
UUID
16 octets
0102statique
060e2b34.0101010a.05200701.08000000
Optionnel : un identifiant de création
GenerationUID est une valeur optionnelle, je ne l'ai que rarement constaté sur un MXF.
Cryptographic Context est le KLV donnant toutes les informations essentielles sur le contexte cryptographique du chiffrement utilisée sur les Encrypted Essence Container et la somme de contrôle (checksum) calculée pour le Message Integrity Code (MIC).
Source Essence Container Label est l'identifiant permettant de définir quel type d'essence est stocké. Ici, nous aurons l'UUID 060e2b34.04010107.0d010301.020c0100 indiquant que c'est un JPEG2000 Picture Element - Frame Wrapped
Cipher Algorithm est l'identifiant qui va définir l'algorithme utilisé pour le chiffrement des essences. Ici, nous aurons l'UUID 060e2b34.04010107.02090201.01000000 qui correspond à AES-CBC-128 (page 8). Vous avez un descriptif de l'algorithme AES-CBC dans un chapitre spécifique.
Message Integrity Code Algorithm est l'identifiant qui va définir l'algorithme utilisé pour la somme de contrôle (checksum) des essences. Ici, nous aurons l'UUID 060e2b34.04010107.02090202.01000000 qui correspond à HMAC-SHA1-128 (page 8).
Cryptographic Key ID est un identifiant important car il sera utilisée pour faire lien entre différentes parties de métadonnées. Cryptographic Key ID n'est pas la clef AES, c'est un simple identifiant défini par avance qui servira de "point commun" à plusieurs éléments dans l'univers magique du cinéma numérique. Cet identifiant doit être généré à chaque génération d'une nouvelle clef AES (ou alors définir manuellement cet identifiant si la clef AES existe déjà qui a servi à chiffrer le MXF en question).
Notez que nous retrouverons KeyId également dans les CipherValue dans notre KDM. Mais cela est en dehors du scope de ce paragraphe, reportez-vous à la page KDM pour plus d'informations.
Les KeyId sont les Cryptographic Key ID de chaque MXF.
En résumé: Cryptographic Key ID (MXF) == KeyId (CPL) == KeyId (KDM)
Message Integrity Code (MIC)
Le Message Integrity Code (MIC) est une somme de contrôle (checksum) permettant de déterminer si nos données sont correctement là et n'ont pas été corrompues ou altérées : elle permet de vérifier l'intégrité des données.
Conceptuellement, un checksum est le résultat d'un calcul effectué sur un ensemble d'octet.
Il existe plusieurs types de calcul, plusieurs algorithmes, des plus simples aux plus complexes, des plus fiables aux plus vulnérables. Elles sont appelées fonctions de hashage. Par exemple, CRC32, MD5, SHA, BLAKE, ...
Pour le cas d'un MXF DCP, le Message Integrity Code (MIC) doit être généré via l'algorithme HMAC-SHA1-128 :
HMAC va utiliser la fonction de hashage SHA-1 afin de générer un hash sur nos données avec un "enrobage" supplémentaire en utilisant la clef secrète pour chiffrer.
La combinaison de HMAC + SHA-1 permet d'avoir un checksum qui peut être utilisé à la fois pour du contrôle d'intégrité des données et également pour valider son authenticité : sans sa clef secrète, le checksum sera différent.
Des algorithmes ouverts, publics et largement utilisés. Des implémentations disponibles dans tous les langages de programmation et des données disponibles prêt au hashage, tout semble être dans le meilleur des mondes. Sauf ... qu'il existe (encore) une subtilité propre à SMPTE.
Comme nous le voyons depuis tout à l'heure - que ce soit au niveau de la norme SMPTE ou au niveau des outils manipulant des MXF - il est indiqué que l'algorithme utilisé pour calculer le Message Integrity Code (MIC) est HMAC-SHA1-128. Rien de plus.
Sauf si on s'attarde sur le paragraphe de l'item MIC (SMPTE 429-6 - paragraphe 7.10), il existe une petite subtilité posée comme cela et - si nous n'y prêtons pas forcément attention - elle peut faire toute la différence :
« The key used in the MIC algorithm (MICKey) is derived from the key (CipherKey) referred to by Cryptographic Key ID using the combination of algorithms defined in Appendix 3.1 and Appendix 3.3 of FIPS 186-2. Specifically the MICKey shall equal to x1 per Appendix 3.1 using CipherKey as the seed-key XKEY, setting XSEEDj = 0 and constructing the function G(t,c) per Appendix 3.3. In addition, since Appendix 3.1 is being used as a general random number generator, the term “mod q” in step 3.c shall be omitted, per the “General Purpose Random Number Generation” of the Change Notice 1 addendum. x0 shall be discarded. »
SMPTE 429-6 - Paragraphe 7.10 - MIC
(fair-use)
Sous tout ce charabia se cache une étape essentielle : On doit appliquer une fonction de dérivation de clef (Key Derivation) sur notre clef initiale dont la définition se trouve dans la norme FIPS 186-2, Section « General Purpose Random Number Generation » (Appendix 3.1).
Sans cette étape, notre calcul HMAC-SHA1-128 ne donnera jamais le bon résultat. Je n'ai aucune idée précise des raisons pour cette étape supplémentaire. Probablement pour empêcher l'utilisation d'une méthode d'attaque permettant de retrouver la clef d'origine qui a servi lors du calcul HMAC.
En quelques mots : on prend une clef, on la triture tellement qu'elle donne une nouvelle clef.
Si vous appliquez votre clef initiale à votre HMAC-SHA1-128 sans passer par la case "dérivation de clef", vous n'obtiendrez qu'un mauvais hash. Il faut donc en amont créer cette clef dérivée puis l'appliquer à notre HMAC-SHA1-128.
Au final et en résumé, le véritable algorithme utilisé est HMAC-SHA1-128 + FIPS-186-2-GPRNG.
Et là, vous obtiendrez un checksum compatible SMPTE.
Faire un schéma explicatif + implementation en Python
Et la clef ?
Pour notre HMAC-SHA1-128, nous avons besoin d'une clef de 128 bits (16 octets).
Et quelle clef avons-nous à disposition et qui serait de 128 bits ?
Notre clef AES, bien entendu !
A l'aide de ce programme permettant de générer une dérivation FIPS-186-2-GPRNG sur notre clef AES 00000000000000000000000000000000, elle deviendra alors 55ACAD4D81EF20B346F80F4A2BF74A28: c'est cette dernière que nous devons utiliser avec notre algorithme HMAC.
Nous reviendrons sur le calcul de cette dernière plus tard.
Les données utilisées pour le checksum
Il existe une dernière petite subtilité : le checksum n'est pas calculé sur l'ensemble des données mais seulement sur une portion.
La somme de contrôle utilisera les éléments suivants pour son calcul :
Nom
Taille (octets)
Format
Position
Encrypted Source Value
Initialization Vector (IV)
16
Offset 68
Check Value
16
CHUKCHUKCHUKCHUK
( Plaintext Data )
Variable
Encrypted Data
Variable
TrackFile ID - Length
4
BER long-format coding - 0x83
TrackFile ID - Value
16
UUID
Sequence Number - Length
4
BER long-format coding - 0x83
Sequence Number - Value
8
Integer
MIC - Length
4
BER long-format coding - 0x83
Il n'y a pas besoin de déchiffrer les données dans Encrypted Data ni Check Value, il faut lire les données brutes - sans aucun traitement.
Si on veut la faire rapide (et sans respecter les tailles en cas de changement), ce seront les données entre l'octet 68 et l'octet -20 de la fin (on ne lit pas les 20 octets du MIC, bien entendu). (Astuce Python:value[68:-20]).
Calcul d'un hash MIC
Pour nos besoins, la Derivation Key de notre clef AES sera déjà fixée dans le code.
Si nous lançons notre programme, nous obtenons un MIC calculé :
$ ./mxf-encrypted-hmac.py "encrypted-key-00000000000000000000000000000000.mxf"
(...)
TrackFile ID Length : 83000010
TrackFile ID Value : 89af85f04a1545ec8a769008829b2029
Sequence Number Length : 83000008
Sequence Number Value : 0000000000000001
Message Integrity Code (MIC) Length : 83000014
Message Integrity Code (MIC) Value : 5b594d66d09cf6ddfda8f6e691e4291ea7097bc8
Calculate MIC = 5b594d66d09cf6ddfda8f6e691e4291ea7097bc8
Nous voyons de suite que notre calcul est le même que le MIC Value inscrit dans le KLV.
En version réduite, vous pouvez même vous permettre de faire cela en Python :
(...)
# read Value
# value = io.BytesIO(value) # on ne va pas utiliser io.BytesIO sur value
(...)
+--------------------------------------------------------------------------------
| derivation_key = b'\x55\xAC\xAD\x4D\x81\xEF\x20\xB3\x46\xF8\x0F\x4A\x2B\xF7\x4A\x28'
|
| # Calculate HMAC
| digester = hmac.new(
| key=derivation_key,
| msg=None,
| digestmod=hashlib.sha1
| )
|
| digester.update(value[68:-20])
| print("Calculate MIC = %s" % digester.hexdigest())
+--------------------------------------------------------------------------------
Ecrire nos propres KLV cryptographiques
Alors que nous avons vu précédemment comment lire des KLV cryptographiques, nous allons voir maintenant comment en écrire !
Pour cela, nous aurons deux approches : soit via une bibliothèque, soit par nous mêmes.
Dans le milieu, il existe deux bibliothèques reconnues :
MXFLib, créée par l'un des créateurs du format MXF et gérant l'ensemble des spécifications MXF mais qui semble un peu abandonnée depuis des années.
ASDCPlib, une bibliothèque plus orientée pour la gestion des MXF DCP/IMF et encore maintenue.
La dernière étant la plus utile pour nos besoins, nous nous tournons vers cette dernière.
Avec ASDCPlib
ASDCPlib intègre de base des outils en ligne de commande qui permettent de faire par exemple de la création de MXF, du unwrapping, de la vérification, etc...
Mais ici notre but n'est pas d'utiliser les outils tout-fait mais de coder notre propre programme - en C++ - afin de créer des KLV cryptographiques. Pour le coup, avec asdcplib, il serait plus compliqué de faire QUE des KLV au lieu de faire directement un MXF complet et chiffré, alors autant en profiter :)
Ce code est un proof-of-concept, il va générer un MXF qu'avec une seule frame chiffrée :
#include <AS_DCP.h>
#include <KM_prng.h> /* FortunaRNG */
#include <Metadata.h> /* MXF:: */
using namespace ASDCP;
int main(void) {
WriterInfo Info;
JP2K::MXFWriter Writer;
JP2K::FrameBuffer FrameBuffer(1024 * 1024);
JP2K::PictureDescriptor PDesc;
JP2K::SequenceParser Parser;
// AES
AESEncContext* Context = 0;
const byte_t aes_key[16] = {
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00
};
Kumu::FortunaRNG RNG;
byte_t iv[CBC_BLOCK_SIZE];
// HMAC
HMACContext* HMAC = 0;
// Set Header
Info.LabelSetType = LS_MXF_SMPTE;
Kumu::GenRandomUUID(Info.ContextID);
// AssetUUID == TrackFile ID (MIC)
Kumu::GenRandomUUID(Info.AssetUUID);
// Set Cryptographic
Kumu::GenRandomUUID(Info.CryptographicKeyID);
Info.EncryptedEssence = true;
Context = new AESEncContext;
Context->InitKey(aes_key);
Context->SetIVec(RNG.FillRandom(iv, CBC_BLOCK_SIZE));
// Set HMAC
Info.UsesHMAC = true;
HMAC = new HMACContext;
HMAC->InitKey(aes_key, Info.LabelSetType);
// Set Parser from files
Parser.OpenRead("essences/JPEG2000/");
Parser.FillPictureDescriptor(PDesc);
// Go to the first file
Parser.Reset();
// Open MXF
Writer.OpenWrite("dump.mxf", Info, PDesc);
// --- foreach frame --------------------------------------
// Read each frame (only one here)
// Each call of ReadFrame() shift to the next frame
// ReadFrame() returns a zero if no new frame
Parser.ReadFrame(FrameBuffer);
FrameBuffer.PlaintextOffset(0); // force no plaintext
// Write each frame into MXF (only one here)
Writer.WriteFrame(FrameBuffer, Context, HMAC);
// --------------------------------------------------------
// Close MXF
Writer.Finalize();
// Show 256 bytes from JPEG2000
FrameBuffer.Dump(stderr, 256);
// Show all metadatas from JPEG2000
JP2K::PictureDescriptorDump(PDesc);
return 0;
}
Note: Ce code se veut ultra-simplifié. Par exemple, nous ne vérifions pas les retours des fonctions (à l'aide d'un Result_t). Principalement pour avoir une vision rapide des différentes étapes entre les fonctions et éviter du code inutile à la compréhension.
Pour expliquer quelques principes de la librairie asdcplib :
Parser.OpenRead va lire un répertoire et indexer chaque image JPEG2000 dans un index interne. A chaque appel de Parser.ReadFrame, ce dernier va lire le fichier suivant dans sa liste, puis remplir le FrameBuffer qui sera utilisé juste après par Writer.WriteFrame pour créer un KLV Essence. Dans notre code, on ne fait que lire la première image. Mais on devrait boucler sur Parser.ReadFrame et Writer.WriteFrame pour ajouter chaque fichier dans le MXF.
Comme cela, rien de bien compliqué. Le plus "difficile" étant de calculer le Length au format BER.
Nous avons deux approches possibles :
Soit on la fait simple et on considère que la taille de Value est de 40 octets : Deux items à 20 octets :
2 octets pour son Local Tag,
2 octets pour sa taille de valeur
16 octets pour stocker l'UUID
Soit nous allons créé notre Value en entier puis nous calculerons sa taille (qui nous donnera 40 octets).
Nous allons partir sur la dernière approche car plus les KLV au format Local Sets vont devenir complexe, plus il sera difficile de faire comme avec la première approche.
Nous allons commencer par créer les deux items : Instance ID et Context SR.
Leurs Locals Tags sont respectivement 3C0A (Instance ID) et FFFF (Context SR).
Les deux valeurs de ces deux items seront des UUID, donc leurs tailles seront de 16 octets chacunes.
En hexadécimal, 16 donne 0x10. Et sur deux octets: 0x0010 : cela sera la taille de notre item.
La valeur de Instance ID est liée à un UUID déjà définie dans un précédent KLV DM Framework -> DM Segment - que nous n'aurons pas dans notre exemple. Nous définirons alors notre propre valeur arbitrairement.
La valeur de Context SR est liée à l'UUID de notre prochain KLV Cryptographic Context -> Instance ID - qui n'existe pas encore. Donc pour celui-ci nous pourrons créer un UUID aléatoire.
Par exemple, la taille de instance_id_uuid est de 16 octets. A l'aide de to_bytes, nous demandons explicitement une conversion de ce nombre (un integer) en une valeur en byte (donc 0x10) et dans une représentation de 2 octets (donc 0x0010).
La taille de instance_id_length et context_sr_length seront 0x0010.
Nous allons créer nos deux items avec nos différents LocalTags (3C0A et FFFF) en concaténant LocalTags + Taille + UUID :
Cela donne par exemple pour item_instance_id : 3C0A00106DFA3D838A8045FDADBE8A65DBD2D1A5
Nous allons créer enfin la Value de notre KLV en fusionnant nos deux items Instance ID et Context SR :
value = item_instance_id + item_context_sr
Et maintenant, on va calculer le Length de notre KLV au format BER long-form-coding en 4 bytes (donc un entête à 0x83) en récupérant la taille de notre Value :
Nous voila avec notre premier KLV ! :)
Passons maintenant au KLV du Cryptographic Context
2/3 - KLV Cryptographic Context
Ce KLV est aussi simple que le précédent, il a juste plus d'items.
Instance ID (3C0A) est une référence à notre précédent KLV Cryptographic Context et son item Context SR que nous avons généré aléatoirement.
Context ID (FFFE) est une référence à nos futurs Encrypted Essence et à son item Cryptographic Context Link, on aura donc à générer un UUID aléatoire qu'on réutilisera plus tard.
Source Essence Container Label (FFFD) sera pour notre exemple 060e2b34.04010107.0d010301.020c0100 car mentionnant que c'est un JPEG2000 Picture Element - Frame Wrapped
Cipher Algorithm (FFFC) et MIC Algorithm (FFFB) ont aussi leur propres labels :
060e2b34.04010107.02090201.01000000 pour AES-CBC-128
060e2b34.04010107.02090202.01000000 pour HMAC-SHA1-128
Cryptographic Key ID (FFFA) va être généré aléatoirement.
Voici un schéma rapide de comment doit être ce KLV :
Et maintenant, nous concaténons tous nos items pour créer la Value de notre KLV et on calcule notre Length :
value = item_instance_id \
+ item_context_id \
+ item_essence_label \
+ item_cipher_algo \
+ item_mic_algo \
+ item_key_id
# BER format (long-form-coding)
length = b'\x83' + len(value).to_bytes(3, byteorder='big')
On rajoute notre Universal Label de Cryptographic Context, son Length et sa Value :
cryptographic_context_ul = b'\x06\x0E\x2B\x34\x02\x53\x01\x01\x0D\x01\x04\x01\x02\x02\x00\x00'
cryptographic_context = cryptographic_context_ul + length + value
Et voila !
Nous avons notre Cryptographic Context
Passons maintenant à notre plat de résistance : Encrypted Essence Container
3/3 - KLV Encrypted Essence Container
Souvenez-vous, notre Encrypted Essence Container est d'un type différent que nos précédents KLV : nous étions sur des KLV Local Sets et nous passons à un KLV Variable-Length Pack : nous n'avons plus d'item.LocalTag, seulement des item.Length et item.Value.
Nous avons aussi beaucoup d'items présent : Cryptographic Context Link, Plaintext Offset, Source Key, Source Length et Encrypted Source Value qui sont la base de notre Encrypted Essence Container (nous mettons de côté la partie MIC pour l'instant).
Commençons par Cryptographic Context Link avec notre context_id_uuid défini dans notre précédent KLV :
En premier, on calcule la taille de notre item : ne pas oublier que contrairement à nos précédents item.Length, ceux-là respectent le format BER, donc nous aurons un petit entête BER (0x83). Notre item sera donc 0x83000010 et notre UUID.
Pour Plaintext Offset, c'est un peu plus compliqué :
Nous ne voulons pas utiliser Plaintext Offset, sa valeur sera donc à 0. Par contre, il doit être sur 8 octets. Nous prenons donc notre petit 0 tout seul et on va l'intégrer dans une suite de 8 octets. On aura donc simplement 0x0000000000000000. Et notre item sera donc 0x830000080000000000000000
Passons maintenant à Source Key qui est le type de l'essence et comment elle est stockée. Notre valeur sera le label pour un Picture Essence - Line Wrapped Data, Not Clip Wrapped, J2C Picture qui est 060e2b34.01020101.0d010301.15010801
Rien à dire de plus, on a déjà vu cela précédemment.
On va passer à Source Length : cet item est la taille de la source, donc la taille de notre frame. Pour notre exemple, on va simplement récupérer la taille de notre fichier JPEG2000. Notez que si vous avez déjà le contenu en mémoire, os.path.getsize(...) est inutile.
Comme vous voyez, c'est identique à avant, la seule subtilité étant de récupérer la taille de notre frame JPEG2000.
Nous passons maintenant à notre (gros) item Encrypted Source Value.
C'est à partir de ce moment que nous allons monter un peu en difficulté. On va jouer avec la cryptographie.
Pour des raisons de simplicité, nous allons faire des raccourcis, comme lire le fichier en entier d'un coup et notre clef de chiffrement AES sera simplement que des zéros.
Puis nous définissons notre coeur cryptographique :
Notre Initialization Vector (IV) de 16 octets sera généré aléatoirement à chaque appel.
Avec notre handler encryptor nous pouvons maintenant chiffrer !
On déjà chiffrer notre CheckValue : obligatoire, souvenez-vous, sinon notre chiffrement final ne sera pas correct.
Nous avons déjà notre CheckValue chiffré, passons maintenant aux données de l'image, une frame JPEG2000 4K d'une taille de 40136 octets :
with open("frame.j2c", "rb") as file:
source_content = file.read()
Nous n'avons fait pas dans la subtilité ni dans l'optimisation, nous avons lu entièrement notre fichier JPEG2000.
Et nous chiffrons directement source_content avec cependant une petite surprise :
Vous remarquez que nous créons un padding : nous utilisons un modulo 16 qui va nous donner combien il y a d'octets en trop et nous allons retrancher ce résultat à une taille de bloc de 16, qui nous donnera le nombre d'octets manquant, et cela rapidement.
Un bref passage sur le principe de notre calcul (modulo et minus), avec des exemples et une taille de source_content égale à 40136 (octets) :
#------------------------
# Taille 40136
#------------------------
# On fait un module 16 sur notre taille pour avoir le nombre d'octet dans le dernier bloc :
>>> 40136 % 16
8
# 8 octets dans le dernier bloc,
>>> 16 - 8
8
# on doit donc rajouter 8 octets pour faire un dernier bloc de 16 octets
#------------------------
# Taille 40140
#------------------------
# Prenons une taille de 40140 octets :
>>> 40140 % 16
12
# 12 octets dans le dernier bloc,
>>> 16 - 12
4
# on doit donc rajouter 4 octets pour faire un 16 octets
#------------------------
# Taille 40149
#------------------------
# Prenons une taille de 40149 octets :
>>> 40149 % 16
5
# 5 octets dans le dernier bloc,
>>> 16 - 5
11
# on doit rajouter 11 octets pour faire 16 octets
#------------------------
# Exception :)
#------------------------
# Petite exception, prenons une taille multiple de 16 :
>>> 40144 % 16
0
# On constate que nous n'avons pas d'octet en trop, tout est parfaitement normal
# Sauf que si nous faisons :
>>> 16 - 0
16
# Cela rajoute quand même un bloc de 16 octets :)
# Ce n'est pas très grave dans notre cas car rajouter des octets en plus
# n'a pas beaucoup d'importance tant que nous arrivons à un multiple de 16.
# Le padding sera supprimé lors du déchiffrement.
Notez que c'est une approche pour faire rapidement du padding, il en existe d'autres.
Maintenant que nous avons nos principaux items pour Encrypted Source Value : IV, CheckValue et EncryptedData, nous pouvons créer notre Encrypted Source Value en les concaténant :
encrypted_source_value = iv + checkvalue + encrypted_data
Il nous reste plus qu'à créer le item.Length de Encrypted Source Value :
Nous avons maintenant tous nos items majeurs pour enfin créer la Value et le Length de notre KLV :
# Création de Value
value = item_cryptographic_context_link \
+ item_plaintext_offset \
+ item_source_key \
+ item_source_length \
+ item_encrypted_source_value
# Création du Length
length = b'\x83' + len(value).to_bytes(3, byteorder='big')
Il nous reste plus qu'à créer notre KLV avec son Universal Label pour Encrypted Essence Container, le Length et la Value :
encrypted_essence_container_ul = b'\x06\x0E\x2B\x34\x02\x04\x01\x01\x0D\x01\x03\x01\x02\x7E\x01\x00'
encrypted_essence_container = encrypted_essence_container_ul + length + value
Et voila !
Nous avons notre KLV Encrypted Essence Container avec notre frame JPEG2000 chiffré à l'intérieur.
Maintenant, nous allons simplement écrire ces trois KLV dans un fichier. Bien entendu, ce fichier ne marchera jamais dans un lecteur MXF lambda, il faudrait ajouter les quelques 20 KLV supplémentaires et nécessaires pour être parfaitement compatible MXF SMPTE.
Nous allons créer un fichier de sortir juste pour voir si notre lecteur de MXF mxf-reader lit correctement les différents KLV :
with open("encrypted-klvs.bin", "wb") as file:
file.write(cryptographic_framework)
file.write(cryptographic_context)
file.write(encrypted_essence_container)
Lançons notre programme pour générer ce faux MXF :
$ ./mxf-create-klv-encrypted.py
On se retrouve avec un fichier encrypted-klvs.bin de 40.448 octets que nous allons analyser avec sa clef de déchiffrement :
L'analyse indique que tout s'est déroulé correctement. Nos trois KLV sont correctement placés et avec la clef de déchiffrement, nous avons pu déchiffrer la frame JPEG2000 et en extraire des métadonnées provenant de l'image directement. Nous constatons également que nos différents liens d'UUID sont correctes. Et enfin, nos checksums entre notre JPEG2000 d'origine et celui qui a été extrait sont parfaitement égaux :
$ shasum -a 256 "essences/JPEG2000/frame.j2c" "extract.j2c"
b469a8333a8ad708becdfc7544f180c1198b12722a2051b90c66b5ba58ded825 "essences/JPEG2000/frame.j2c"
b469a8333a8ad708becdfc7544f180c1198b12722a2051b90c66b5ba58ded825 "extract.j2c"
Nous pouvons réutiliser ce code pour insérer nos KLV cryptographiques dans un MXF complet.
MIC : création
A terminer
Le padding cryptographique et la limite de la bande passante
La spécification DCI mentionne une limite de bitrate, elle est de 250 Mb/s (500 Mb/s pour le HFR et le HDR).
Afin d'avoir la plus grande qualité possible dans l'image, certains laboratoires mettaient la compression du JPEG2000 à son plus bas pour faire correspondre à un bitrate à la limite des 250 Mb/s (ou des 500 Mb/s pour le HFR).
En faisant cela, il arrive parfois un effet de bord : comme nous l'avons vu, la cryptographie AES nécessite un multiple de 16 octets.
Que se passe-t-il si un fichier JPEG2000 n'est pas un multiple de 16 octets ? Un padding va être créée. Dans l'absolu, ce n'est pas grave, ce sont quelques octets en plus dans le KLV.
Mais que se passe-t-il si beaucoup de JPEG2000 ne sont pas des multiples de 16 ? Il y aura donc énormément de padding, donc un surplus d'octets dans chaque KLV. Et donc un dépassement de la limite du bitrate.
Cela ne sera quasiment rien, au lieu d'être à 250 Mb/s, vous serez à 250.001 Mb/s par exemple. Souci : certains players refusent catégoriquement de lire ce type de MXF. Votre DCP sera donc rejeté.
C'est pour cela qu'il est conseillé de demander une compression avec une valeur correspondante de bitrate légèrement en dessous de la limite (par exemple ~245 Mb/s - ou 495 Mb/s en HFR) afin de laisser une légère marge si des paddings cryptographiques sont ajoutés lors de la phase de chiffrement des MXF.
Conclusion
Et voila, vous savez maintenant (quasiment) tout sur un MXF chiffré :-)
Ce paragraphe est probablement perfectible et des éléments peuvent manquer.
Annexe : Codes et techniques
Retrouvez les codes sources et techniques sont disponibles dans une page spécifique : MXF-Codes
Annexe : Identifiants UL & Label
Voici des résumés et explications rapides des différents labels pour la partie cryptographie.
Universal Label : Encrypted Essence Container
Universal Label utilisé comme clé pour identifier les KLV chiffrés.
Label utilisé pour le tag "Essence Container" dans les KLV "Partition Pack Header", "Partition Pack Footer" et "Preface". Il ne sert que comme identifiant (label) dans les metadatas.
Annexe : Des tailles fixes dans un Variable-Length Pack ?
Alors que le KLV est de type Variable-Length Pack et donc que chaque item a son propre item.length pour définir la taille variable de sa item.value, vous remarquerez que - pour tous les items évoqués ci-dessus - nous avons déjà indiqué leurs tailles.
C'est tout simplement parce que les tailles des item.value des items sont déjà fixées dans la norme ! Théoriquement, nous n'aurions pas besoin des item.length dans chaque item (sauf si on a pas la documentation, mais dans ce cas, nous ne saurions pas également à quoi correspond tel ou tels items).
Vous remarquerez aussi que l'item Encrypted Source Value n'est qu'un containeur pour quatre élements (IV, CheckValue, Plaintext Data et Encrypted Data et son padding) mais sans aucun item.length propre à eux : IV est obligatoirement à 16 octets donc cela aurait été inutile, cependant Check Value est défini comme un bloc de 16 octets mais aurait pu être différent tout en restant un multiple de 16 octets, par exemple.
Et enfin, vous remarquerez que l'item Plaintext Offset est un ersatz de Length pour Plaintext Data mais qui ne se trouve pas à côté de lui (ce qui aurait pu être le cas, pour respecter la structure d'un Variable-Length Pack).
On a une partie de Variable-Length Pack mais avec des définitions de tailles fixes comme pour le Fixed-Length Pack et une partie qui semble ressembler à du Fixed-Length Pack (donc sans Length) mais avec une partie variable comme Encrypted Data.
C'est pour tout cela que j'ai surnommé ce type de KLV, un Fucked Pack.
Digital Cinema System Specification, 9.7.5. Integrity Check Codes : Cryptographic data integrity checksums shall be ensured according to the HMAC-SHA-1 algorithm, as specified in FIPS PUB
198a “The Keyed-Hash Message Authentication Code.” (..) The requirements of this section shall be superseded by the FIPS 140-2 or FIPS 140-3
Notes
Si vous tombez sur un Universal Label060e2b34.02040107.0d010301.027e0100 (octet n°8 - Version - à 0x07), c'est également un Encrypted Essence Container mais pour Interop. ↩




{kind=link}